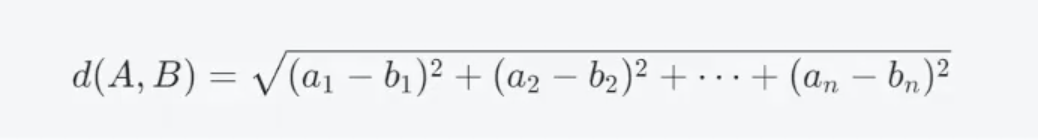综述
整体的线路大概排名:AS23764(CTGNet)≈AS4809(CN2 GIA)>AS9929(CNCNet)>AS9808(CMI)>AS4837(CUVIP)>AS4837(169)>AS4809(CN2 GT)≈AS4134(CN163)
判断方法:
| 网络 | IP地址 |
|---|---|
| CN2 GIA | 59.43.*.*(全部) |
| CN2 GT | 59.43.*.(国外)/ 202.97..*(国内) |
| 163 | 202.97.*.*(全部) |
| AS9929 | 218.105.. / 210.51.. |
| CUVIP | 同AS4837,但走美西(SJC)出口 |
| AS4837 | 联通默认 |
电信
电信:CTGNet≈CN2 GIA>CN2 GT>163直连。
ChinaNet(163网)
ChinaNet(也就是163网),主要城市如LAX、SJC、FRA、LON,回国带宽大,但因电信超卖严重,因此尖峰时段较容易阻塞,同时也常有来自中国境内的流量攻击将出口塞满。价格较低,也是绝大部分普通家宽的默认出境路线。
CN2 GT (Global Transit) CN2 GT(全球过境)
CN2 GT,163与CN2 POP之间统一在上海、广州、北京三个互连点,北京互连点为新增节点。同上一点所属,由于两张网流量交换前也会经过163的汇聚点,因此也较容易因163汇聚点有大量攻击流量导致阻塞,同时因攻击塞满两张网之间的互连也时常发生。
对于跨境互联质量,电信官网承认CN2 GT与ChinaNet质量无异。换句话说就是,CN2 GT集成了电信两张网各自最烂的部分:CN2海外的憨批骨干质量和163出口的傻逼跨境段质量。
欧美地区的CN2 GT或将在接下来规划下线,现有CN2 GT的客户(已知的包括QuadraNet AS8100, 俄罗斯DataLine等)将被切换至163。但正如前文所述,在跨境质量上CN2 GT和163因为是共享C-I段,因此在质量上并不会有差别或者变化。
CN2 GIA (Global Internet Access)
GIA与GT之间所经过的跨境互联段不同(即C-I段),其中GIA有单独的C-I段容量,而GT则与163共享C-I段,因此基于目前的跨境互联质量而言,CN2 GT与163几乎没有差异,但GIA与GT/163则会有明显体验上的差异。该产品在163与CN2两张网之间互连有独立的端口进行互连,互连点也较多,采就近接入原则,但实际上延迟不一定比较好。且因互连点不同关系,实际上有可能会出现某地至北美GT走上海出口,但GIA却走广东出口等等差异。另互连端口在有大量攻击时容易阻塞。特别是南京、北京互连点。
电信报价依据所在地与中国大陆之间的延迟决定,延迟越高价格越低,如北美大约6 USD/Mbps (目前可能已涨价),而香港地区的CN2 GIA单价最高则达到了100 USD/Mbps,底线价格也有接近$80(但应该很少能有以这个价格拉到的)。2022年3月份左右CN2的跨境段容量峰值使用率已超过90%+,电信集团目前已经暂停了部分方向新接的CN2 GIA的订单(除非有释放的带宽资源,释放多少批多少)。
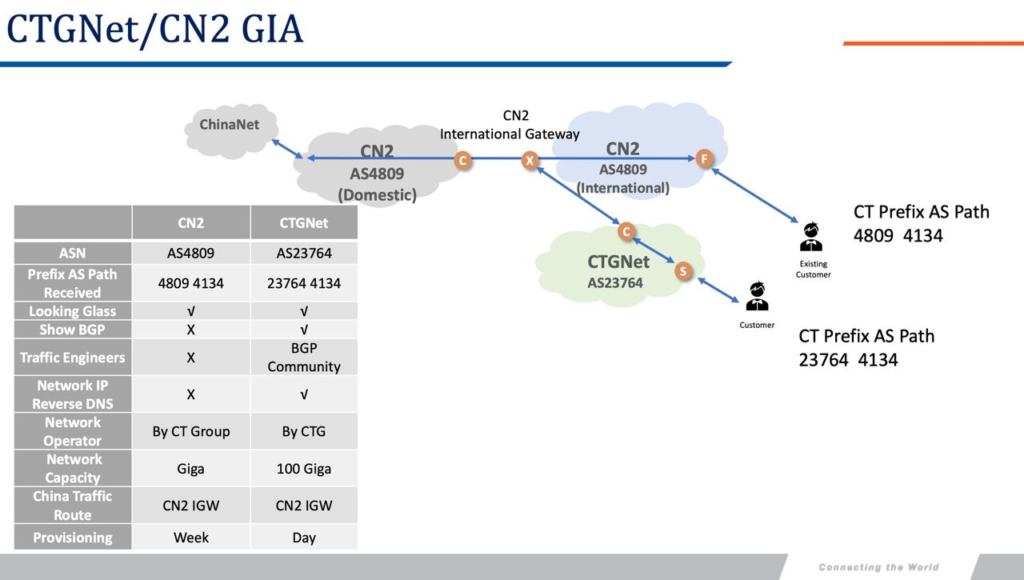
与AS4809直接互联的CN2 GIA产品在亚太和欧洲地区已经下线,目前新接客户需要通过CTGNet。
CTGNet (AS23764)
由于通过CTG/CTA/CTE购买GIA带宽需要中国电信集团级别审批合约,因此CTG自己搞了个CTGNet(自卖自销系列),据大佬介绍CTGNet订购的带宽合约目前暂不需要集团审批。在今年年底某个时间点以后新开的合约都需要走CTGNet签订。目前电信正在将已有的AS4809客户迁移到CTGNet,亚太地区比如香港和新加坡已经迁移不少客户,包括阿里云香港、腾讯等,今后新开的大部分CN2合同都会变成CTGNet的合同。
CTGNet包含了之前的163/CN2 GT和CN2 GIA的接入,区别是根据合约报价来决定最终互联的质量,钱给的多就给你GIA,钱给的少那就是GT甚至163。
目前亚太和欧洲(除俄罗斯以外),原有的CN2 AS4809的客户大部分已经迁移至CTGNet下。
CTGNet常见的骨干网IP开头为 69.194 和 203.22,均在AS23764下。
联通
联通:三网回程GIA > 三网回程9929 > 三网回程4837。
中国联通目前有3个主要ASN:AS4837(中国联通骨干网),AS10099(中国联通国际,CUG)以及AS9929(中国联通工业互联网,CUII,以前的老网通的骨干,简称A网)
一般家宽客户接入的是4837网络,与电信4134类似。国际出口分为北京、上海、广州三部分。比较常见的路由如北京出口承载多数省份的跨境流量,包含日韩北美欧洲俄罗斯等地区;上海出口承载至东亚/东南亚以及北美圣何塞的跨境流量;广州出口承载至港澳/东南亚/北美(洛杉矶)/欧洲部分地区的流量。
联通对其上游宣告的IP段有一定倾向性调整(这实际上也是流量工程和QoS的一部分),例如,对于部分IP段,联通在日本发给NTT的路由prepend了AS PATH,造成的情况就是对于同时接了NTT和其他网络的服务商(比如甲骨文东京接了NTT和TATA),由于AS PATH长度问题,至联通部分IP段(例如153.3.16.1)是NTT经由上海/北京互联回程,而部分IP段(例如 27.11.128.1) 则被送去了其他网络,出现绕美/高延迟的情况。这一点在联通至新加坡Cogent的互联也能看出来(部分段走新加坡的Cogent直接回到联通网内,部分则绕欧至联通与Cogent的欧洲互联)。
10099(CUG)与电信目前的CTGNet类似,提供至大陆方向的差异化接入,包括CUG(10099->4837)和CUG VIP(10099->9929->4837)
9929为老网通骨干网,现在的CUII,其本身负载低,所以被用于为政企提供高质量网络访问,但是缺点在于。。。这张网的跨境互联端点对比4837较少,而且多数互联的容量并不大。。。现在作为联通对标CN2 GIA的产品销售。
普通4837的报价依据互联地区不同而不同,日本/新加坡可以做到$20/Mbps甚至更低的价格。(但还是贵而且和电信一样是Best Effort),香港比日本/新加坡略高一些,≤$25/Mbps,欧洲地区 ≤$5/Mbps。
香港 10099 CN Premium Route (官方名称,实际上就是9929)的报价一般≥ $55/Mbps。
移动
移动线路原本是全部走香港出口的,自2022年初开始,随着上海临港出口启用,在日韩购买了CMI IP Transit的ISP/IDC回到国内部分省份移动的流量会经由上海出口承载,延迟对比绕广东会有所降低。
目前的主要出口还是广州-香港段,IPv6跨境流量路由大部分会出现绕行上海的情况(即使你处在广东)。
注:移动线路的出口表现在不同省份不同线路的差异极大,对于广东、上海来说较好,对于内陆省份较差,需要根据实际情况测试决定
其他
CTGNet (AS23764)/CUG (AS10099) 和 CMI (AS58453)三张网的差异性
三家运营商目前都有趋势将国际客户的IPT业务转移至自身的国际网络下,但是三家的国际网络资源略有差异。
对于电信和联通,CTGNet和CUG提供的包括对客户的IPT接入以及差异化产品(例如普通IPT:CTGNet给到163,而10099给到4837;而对于精品IPT(Premium IP Transit),CTGNet给到的是原有的CN2 GIA产品,CUG给到的则是联通A网9929。这一点也可以从现有路由能看出来。此外,CTGNet和CUG也为两家运营商在海外的移动客户提供网络接入(例如CUniq和CTMO/CTexcel),并且两张网络也用于对应的国内CN2/9929精品网客户就近访问海外资源。CTGNet和CUG目前并不接管两家运营商全部的出海流量。
而对于移动,AS58453 CMI则是国内移动AS9808客户公网跨境的几乎唯一方向,并且移动的海外精品网访问接入是由AS58807来负责的,与电信CTGNet和联通CUG的角色上有较大的区别。
境外VPS购买提示
电信用户如果不买优化线路(GIA/9929/4837/CMI回程/163优化线路等)用电信163回程晚高峰会很慢。
联通用户因为用户量少,出国线路日常就能满足,主流4837回程(推荐9929和软银/GIA/4837和香港CMI)。
移动用户主流CMI回程(推荐香港CMI/GIA和9929/普通线路4837)
整体位置速度:香港>韩国>日本>美国。香港VPS比较贵。