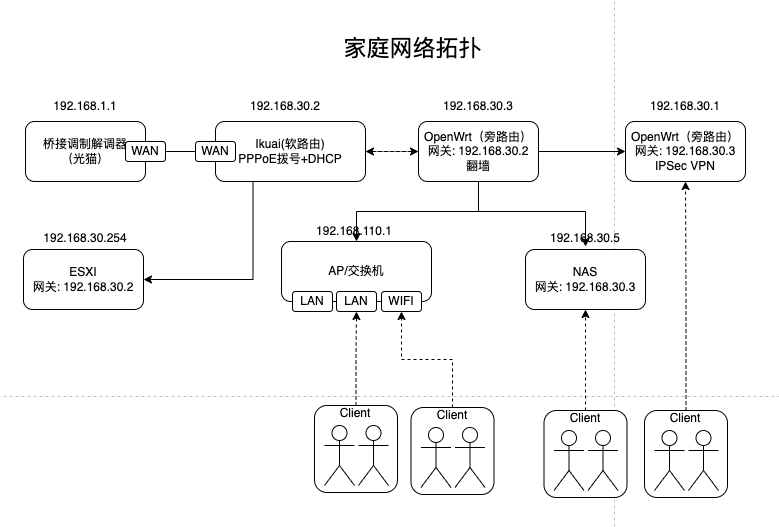
Marquez
开源地址:https://github.com/MarquezProject/marquez
Marquez的优点:
- 界面美观,操作细节设计比较棒
- 部署简单,代码简洁
- 依靠底层OpenLineage协议,结构较好
Marquez的不足:
- 聚焦数据资产/血缘的可视化,数据资产管理的一些功能,需要较多开发工作
相关介绍:https://mp.weixin.qq.com/s/OMm6QEk9-1bFdYKuimdxCw
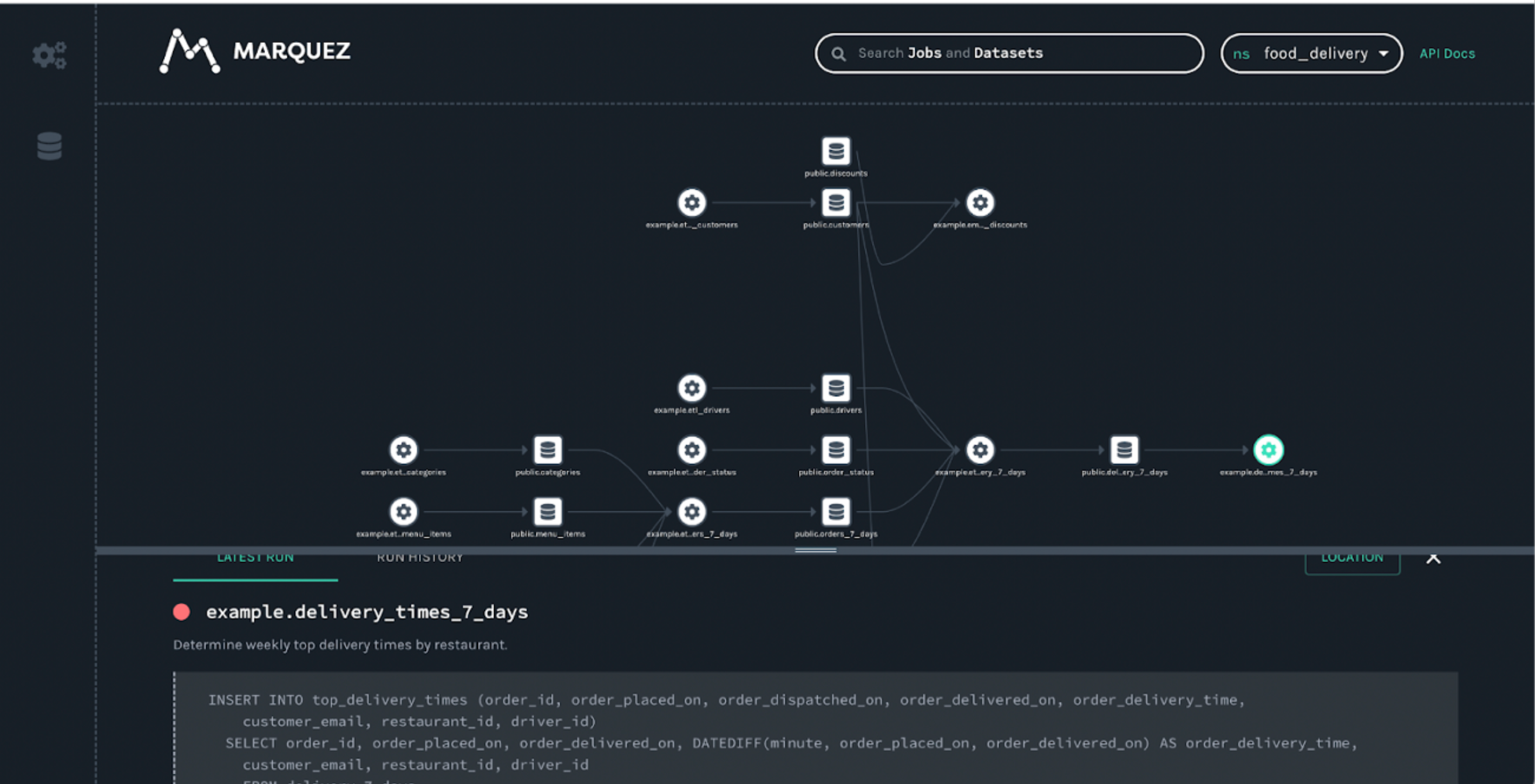
安装及体验
- 克隆项目
1 | git clone git@github-hoey94:hoey94/marquez.git |
- 到项目根目录运行docker
1 | DOCKER_BUILDKIT=1 ./docker/up.sh --seed |
- 访问页面
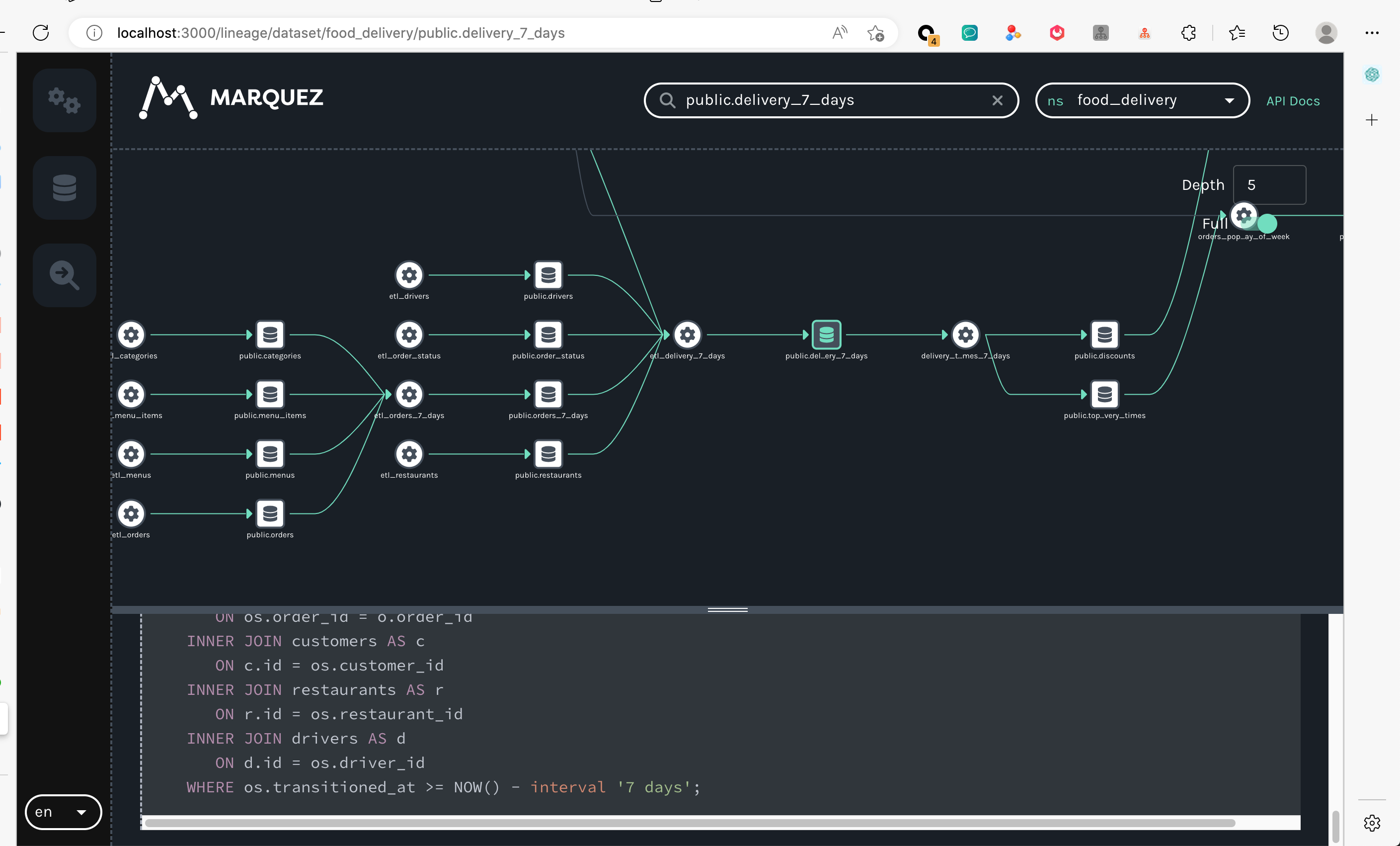
- 简单实用
创建namespace
1 | curl -X POST http://localhost:5000/api/v1/lineage \ |
创建input和output
1 | curl -X POST http://localhost:5000/api/v1/lineage \ |
更多细节可以参考一下下面文章:https://blog.csdn.net/weixin_43947468/article/details/129593234